Understanding Hyperloglog Lokikv Devlog Series
Understanding HyperLogLog: LokiKV — DevLog series
Understanding HyperLogLog: LokiKV — DevLog series
Hello there! This is the first blog in a series of devlogs documenting my journey in developing an in-memory key-value store called LokiKV…
Understanding HyperLogLog: LokiKV — DevLog series

Hello there!
This is the first blog in a series of devlogs documenting my journey in developing an in-memory key-value store called LokiKV (though I’ll likely rename it soon, since Grafana already has Loki). What started as a simple experiment has now grown into a project where I want to add more features and build something truly worthwhile.
In this blog, I’ll discuss the implementation of the HyperLogLog data structure in LokiKV.
What is a HyperLogLog?
To put it simply, HyperLogLog allows us to count unique elements in a stream.
Now, you might think this sounds like a trivial problem — why develop an entire data structure just for this? Well, let me show you why we need it and why it works so well!
How do we normally count elements? We typically store them in an array or a list and retrieve the length of that structure. While this gives us the total count of all elements, counting only the unique elements requires one of the following approaches:
- end up iterating over the entire data structure
- Keep a hashmap/set in place, store the data items within it, and just get the size of the hashmap to get the number of unique counts
These approaches might seem optimal, but consider the second case — what if millions of entries are flowing into your system every second? Do you think your memory can handle storing all that data in a hashmap or a set?
Eventually memory will overflow, your system will crash!!
Enter HyperLogLog
To tackle the problem of counting unique elements efficiently, we were introduced to the concept of HyperLogLog in the 2007 paper HyperLogLog: The Analysis of a Near-Optimal Cardinality Estimation Algorithm 1.
In 2013, a joint effort by Google and ETH Zurich led to the publication of HyperLogLog in Practice: Algorithmic Engineering of a State-of-the-Art Cardinality Estimation Algorithm 2, which introduced an improved version of HyperLogLog known as HyperLogLog++.
HyperLogLog (and its improved version, HyperLogLog++) does not store data directly in a single structure like a list. Instead, it processes data directly from the stream and follows these steps:
- Generate a hashed value for the data item.
- Divide the stream into multiple substreams based on the first p bits of the hashed value.
- Count the number of leading zeros in the remaining n — p bits.
- For each substream, track the maximum number of leading zeros encountered.
This approach significantly reduces the amount of data stored in memory!
Now, we apply the following formula (which I’ve taken from the official research paper):
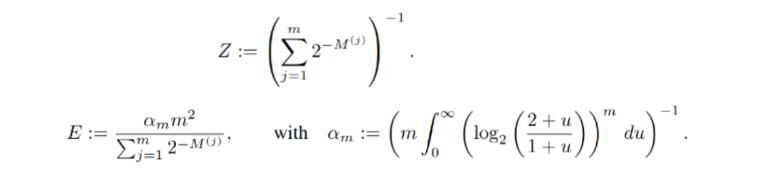
Here E, is the raw estimate, as provided by the original paper. The HyperLogLog++ algorithm has some more clauses to correct for accuracy issues in small and large ranges.

In the equation, M[j] represents the maximum number of leading zeros in the (n — p) bits of the substream at index j (i.e., the substream identified by the first p bits).
Although the equation may seem complex, Google’s paper simplifies the algorithm significantly for implementation. An important point to note is that HyperLogLog uses stochastic averaging, which provides an estimate of cardinality (i.e., the unique count), meaning some level of error is expected. The Google paper focuses heavily on improving the accuracy of this algorithm by addressing special cases where deviations are particularly high.
Implementing in LokiKV
After taking a quick look at the base concept of both of these papers, primarily the equation, I started off with my implementation in rust.
So we have a single struct representing the HLL.
According to the HyperLogLog++ paper2, we are mapping the first P_BITS of the hashed value to the largest number of leading zeros in the remaining bits of the value.
Whenever we get a new element, we calculate a 64-bit hash as suggested in 2 of this value using the DefaultHasher available in rust is the calculate_hash function. Right now we are assuming that the incoming data is of String type but this can easily be expanded to generic types by modifying the function signature.
The add_item function uses the calculate_hash function to get a hashed value for each entry. Then we extract the first P bits from the hashed value to create an entry in the streams map, essentially dividing the data stream into sub-streams.
Now whenever we want an estimate of the cardinality we can call the calculate_cardinality function. Here I have implemented some concepts from the HyperLogLog++ paper2 like range handling and linear counting. Lets break down this particular function:
- We get the harmonic mean by iterating over each substream.
- Based on the value of P, we decide the value of alpha
- Once we generate a raw estimate from the formula seen above, we utilize the correction techniques provided by 2. For short ranges, we utilize Linear counting, while for long ranges we apply some more correction measures to the raw estimate.
What has been completed so far?
In my current implementation, I am able to handle small and medium ranges, while there is some high error rate for very large ranges(for example 1,000,000,000).
If you want to see it in action you can follow the pull request here.
Subsequently once we are done with this PR, I’ll be creating the first ever release for LokiKV. In the meanwhile, if you’d like to try out LokiKV, you can head on to the GitHub repository3 and compile the source code using the steps provided.
Thanks for reading until the end! Stay tuned for more devlogs in the coming weeks.
References
By Akshat Jaimini on February 27, 2025.
Exported from Medium on March 25, 2025.