Keeping Track with Checkpoints and Persistence: LokiKV — DevLog Series
Hello There!
It has been really long since I wrote one of these devlogs but as usual life came in the way, switching job, moving cities… the usual. Now we’re back to working on LokiKV!
In the last devlog, we explored how HyperLogLog, a probabilistic data structure works and is implemented. Today we are going to cover the concept of Checkpoints, persistence and Snapshots.
What are those magical terms?
I originally started out with writing a simple WAL implementation so that I could transition to implementing fault tolerance with Paxos/Raft but soon at my new job I got into a discussion on this with my current Manager. He pointed out a critical mistake in my thought process — WAL needs a previous copy of the database to be replayed upon. This might sound trivial but I had completely skipped this part to rush into the ‘fun-stuff’.
- Persistence: This simply means that we end up dumping the data for a collection to disk. Traditional databases work in a similar fashion where they dump their WAL regularly to the disk. For LokiKV WAL to work, I needed the mechanism to implement persistence.
- Snapshots: Snapshots are previous copies of a database versioned by time. They are not only used for backup, but in databases like PostgreSQL they also come in handy when we have concurrent operations running on the DB(there it is known as MVCC-Multi Version Concurrency Control).
- Checkpoints: This is a process in which the database takes a snapshot of itself on a regular interval. This is essential for ensuring durability and ensuring that the process of replaying the WAL is much faster, since running a WAL file which contains all operations from the moment the instance was started would take a lot of time to repopulate the DB. Checkpoints usually run in the background in databases like PostgreSQL, but we can also force them manually. In LokiKV, I have tried to follow a similar approach.
Implementation details
Coming to the interesting bits now. Let’s recap why we need these three features:
- Persistence: To store db state on disk
- Snapshot: To store time-versioned db states on disk
- Checkpoint: To regularly take snapshots
If you notice carefully, these terms might be different but they are essentially smaller features built on top of one another. Therefore, persistence is actually the core feature and the other build on top of it.
Page: The Base Layer
Traditionally databases utilize the concept of a page to store tuples. In PostgreSQL, tuples are written in 8kb pages and whenever the data is required, the page is pulled into the buffer pool in memory for querying.
Since we are already using an in-memory model in LokiKV, we can simply dump a vector of tuples in bifurcated chunks. As of now the Page implementation a.k.a the StoragePage looks something like this:
Right now this is very rudimentary since I am cloning the tuples again in memory, this might lead to some really bad performance. I’ll most probably update this to use references, but for now we have something.
For flushing the data to disk I initially implemented it based on JSON.As scandalous as this sounds, this was the first implementation of my persistence layer. Since tuples at this point are essentially just key-value pairs, my monkey brain just wanted to get some sort of persistence working and json seemed to be the easiest. In this case the main drawback is the slowness of parsing json for reading back the database.
In the final version that is on the main branch now, we just use the bincode crate in rust, essentially serializing a vector of tuples into a binary file. This is much faster as compared to the previous json implementation and much more in line with how traditional databases store their pages.
On top of the StoragePage , I implemented a separate struct which is responsible for generating pages and regularly dumping them. The Persistor struct looks something like this:
As you can see, the persistor handles the primary directory for storage and it is also responsible for loading this data directly in the preferred collection type. With this we can even load a hashmap collection to a btree collection easily.
For each usage, a separate Persistor object is setup. So we have one for normal persistence and checkpoints as well.
Final Result
We need to setup some env variables for these to work
export PERSIST_DIR=/home/akshatj/dataloki2
export CHECKPOINT_DIR=/home/akshatj/lokidata2
export CHECKPOINT_INTERVAL=5
Now we have the following functionality:
>>> /c_bcust namor
OutputString("CREATE CUSTOM B-TREE MAP COLLECTION")
>>> /selectcol namor
OutputString("SELECT COLUMN")
>>> SET data 12
OutputString("SET")
>>> SET name 'akshat'
OutputString("SET")
>>> /selectcol default
OutputString("SELECT COLUMN")
>>> SET data <BLOB_BEGINS>hello<BLOB_ENDS>
OutputString("SET")
>>> DISPLAY
OutputString("\"data\" -> BlobData([60, 66, 76, 79, 66, 95, 66, 69, 71, 73, 78, 83, 62, 104, 101, 108, 108, 111])")
>>> PERSIST namor
OutputString("PERSISTING namor TO DISK")
>>> PERSIST default
OutputString("PERSISTING default TO DISK")
>>> SHUTDOWN
As you can see, we created a new btree-custom collection, set some data, switched to default and persisted both the collections to disk. In the screenshot below we can see that every 5 seconds, a new snapshot of the entire database was taken
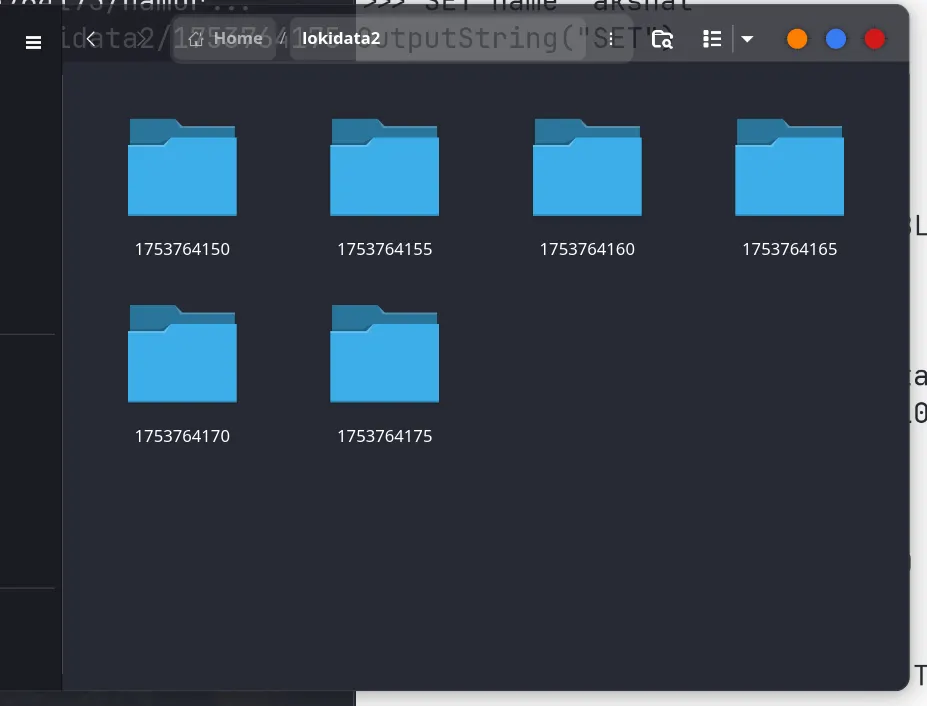
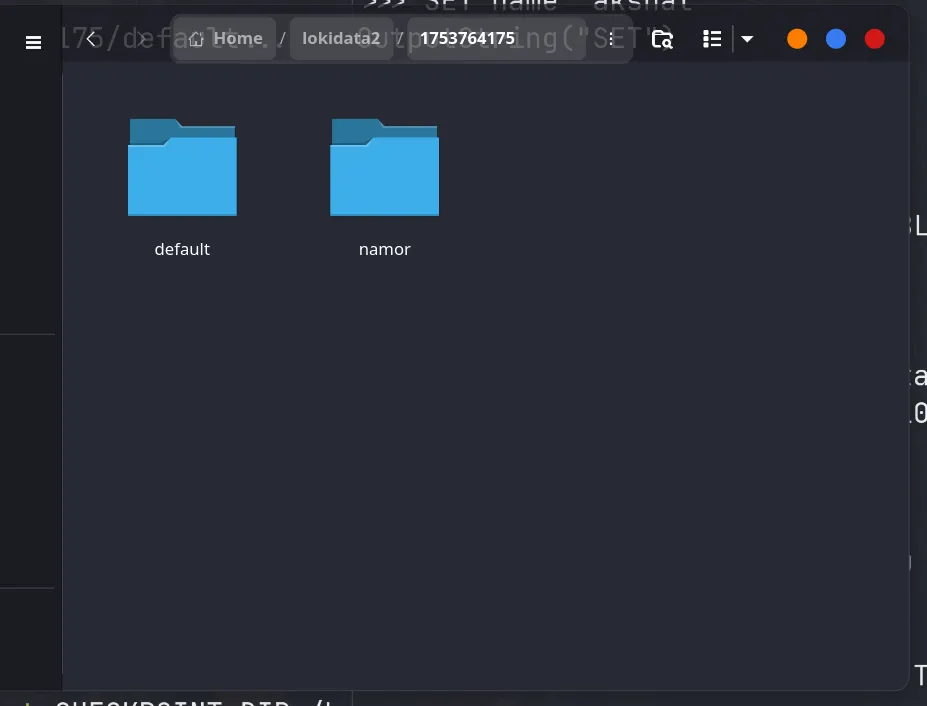
Once the WAL is implemented we can easily load the latest snapshot and replay the WAL upon that.
Next up for Persistence, we can see in the screenshot below that namor and default have been stored in the dataloki2 folder:
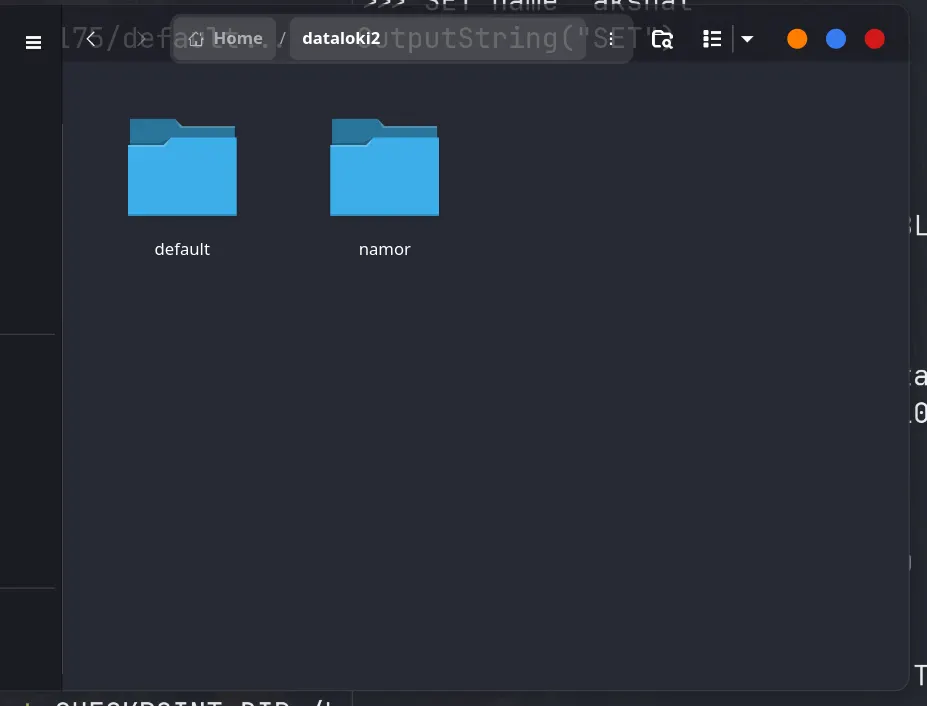
Now let’s try loading these persisted collections:
>>> LOAD_HMAP default
OutputString("LOADED HMAP default FROM DISK")
>>> /selectcol default
OutputString("SELECT COLUMN")
>>> GET data
BlobData([60, 66, 76, 79, 66, 95, 66, 69, 71, 73, 78, 83, 62, 104, 101, 108, 108, 111])
Here you can see that we loaded default back into a hash map based collection. Now lets try loading in the bcust collection namor as a hashmap collection too:
>>> LOAD_HMAP namor
OutputString("LOADED HMAP namor FROM DISK")
>>> /selectcol namor
OutputString("SELECT COLUMN")
>>> GET data
IntData(12)
Right now we can only load collection with its previous name.
What’s Next?
- Make Snapshots incremental, instead of storing a full copy everytime
- Implementing WAL on top of the checkpoint mechanism
- Implementing a COPY command, similar to load but allows us to rename the collection
- Improve persistence by removing extra in-memory tuples.
- Maybe move to implementing RAFT/PAXOS finally :)
Thanks for reading!
To learn more about the project checkout the Github Repository: https://github.com/destrex271/LokiKV