Let’s scale it up: LokiKV Devlog Series #3
Hello There, It has been a very very very long time since I added another entry in the LokiKV Devlog series! So this mini-blog post is sort of a filler to get you upto speed on the current stage of the project.
Towards the end of the last devlog post, I had mostly left off things after implementing the check-pointing feature with an aim to finally implement a Write Ahead Log within the system and also start working on a distributed deployment using algorithms like Paxos.
Are we at the WAL yet?
Yep! In this long gap, I was able to wrap up the WAL implementation but before I implemented it I had to rework how most of these settings like Checkpoint directory, frequency etc.. could be controlled. Another challenge was to actually understand if or not WAL actually fits into the current architecture.
Why do we need a WAL in LokiKV?
Do Not implement anything just because existing systems do it. Reason about it and if it fits your requirements, go ahead. Crux: Question Everything.
Durability. Thats it! The initial purpose of having a WAL in any type of data management system is durability. Again, this is not some brand new knowledge, this stuff has been known for decades now but just to recap — checkpoints also ensure durability but there are certain drawbacks:
- No guaranty of preserving operations that might happen between checkpoints
- Taking a snapshot is very expensive, therefore the interval needs to be large enough.
Given the above two points, WAL fits in perfectly. Instead of calculating a snapshot after every write operation, just simply record it on a file on disk and clear it out once the checkpoint catches up.
With all of this the current architecture of LokiKV looks something like this:
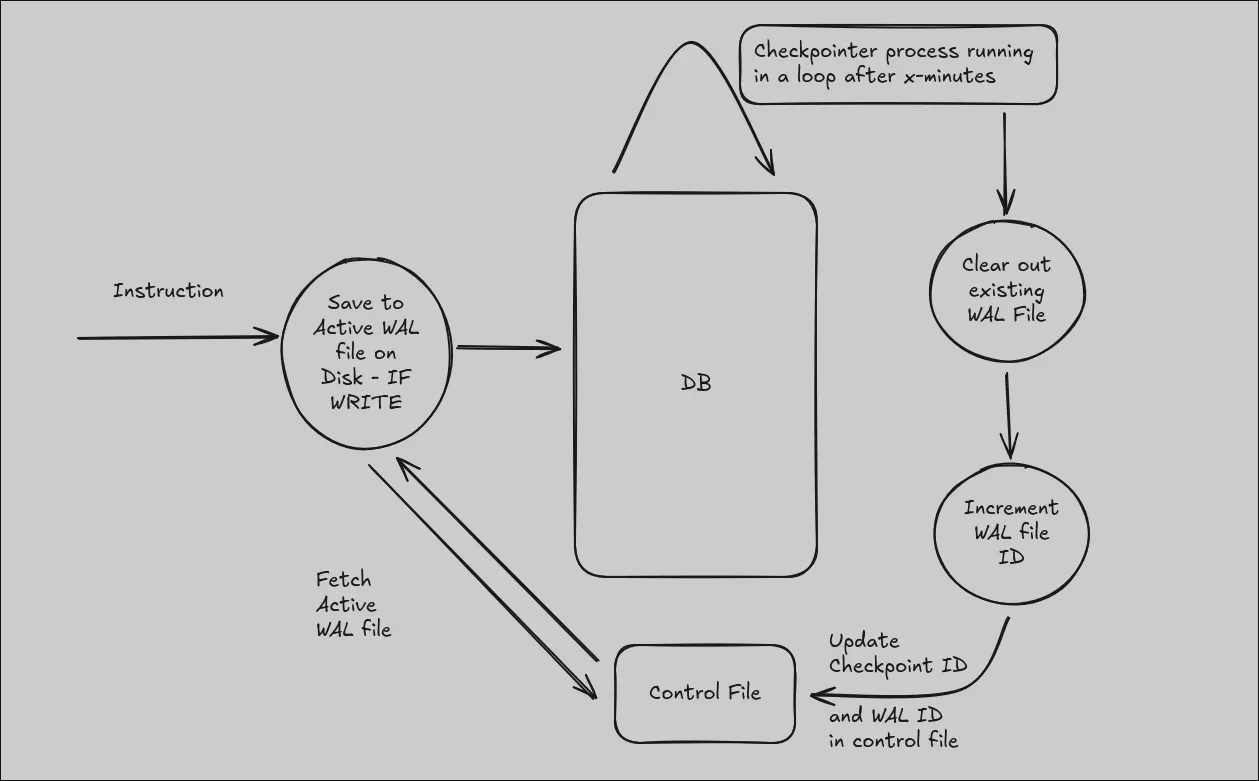
You might have guessed it by now, this looks an awfully slimmed down version of how WAL works in PostgreSQL! Although PostgreSQL has many fancy features like timelines etc, I needed a much more stripped down version of the WAL for the following purposes:
- As mentioned before, durability
- For the upcoming replication setup feature. In case of replication, sending a WAL file makes much more sense.
For the replicated setup, I haven’t implemented the archive feature since I am not 100% confident that it is the way to go. As I mentioned at the beginning of this section, I am questioning every choice that I am making for this project.
What’s up with the ‘Control File’?
As you can see in the architecture diagram above that I am referring to a ‘Control File’. The main purpose of this file is to keep track of the system state during execution and also provide basic configurations like which directories should be used for checkpoints and WAL files etc. The control file is a simple toml file which looks something like this:
last_wal_timeline = 5
last_checkpoint_id = 3
checkpoint_directory_path = "/home/akshat/lokikv/checkpoints"
wal_directory_path = "/home/akshat/lokikv/wal"
As you can see, nothing complicated! And again, if you observe carefully, this is also a very, very stripped down version of how PostgreSQL utilizes a control file to keep track of database state. In PostgreSQL Control File becomes critical for many things related to database startup. For example, based on the control file values, it is determined in which mode should PostgreSQL be started.
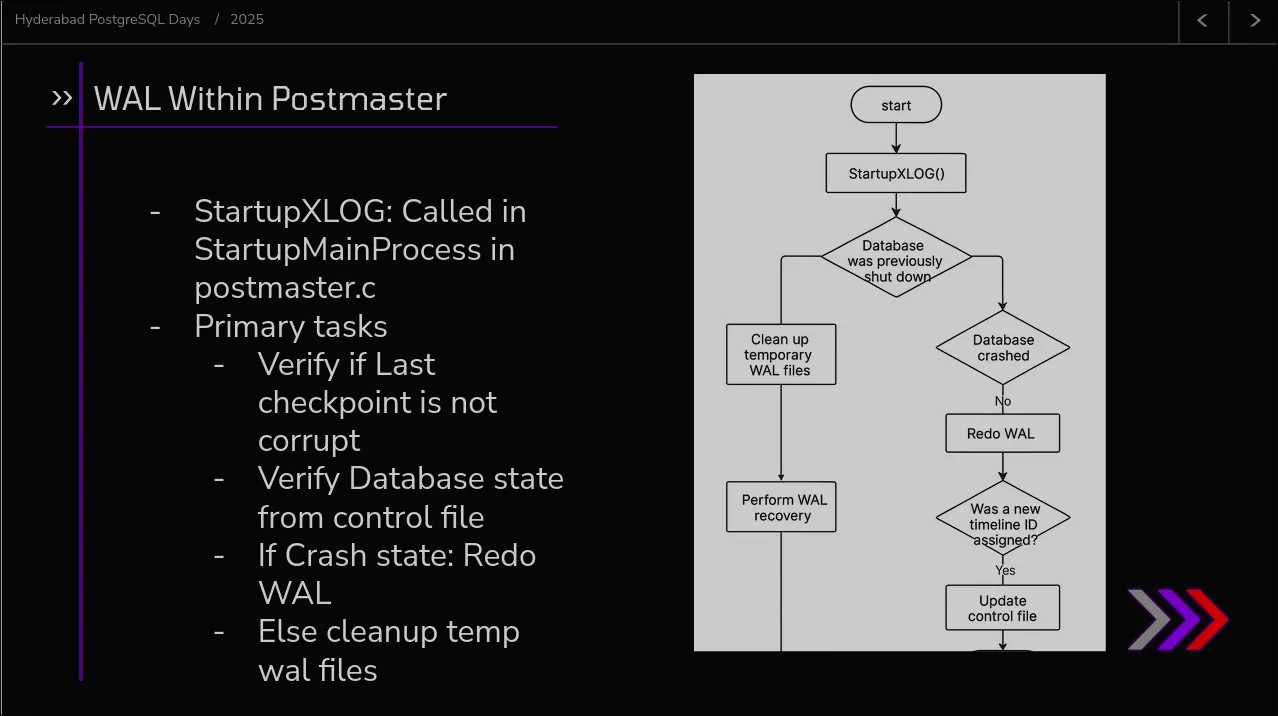
For LokiKV the control file is pretty self-explanatory:
- Last WAL Record file name
- Last Checkpoint ID
- Where to store checkpoints
- Where to store WAL records
If you checkout the current version of the Control File structure in the source code you’ll notice two more fields:
#[derive(Serialize, Deserialize, Clone)]
pub struct ControlFile {
last_wal_timeline: u64,
last_checkpoint_id: u64,
checkpoint_directory_path: String,
wal_directory_path: String,
current_leader_value: Option<u64>,
self_identifier: Option<u64>,
}
The new fields will be used to assign an identifier to the current node in a replicated setup and to store the value of the active leader node for reference. The current_leader_value is mutable and would be updated whenever a proposal from some other node/itself is accepted by the majority of the nodes in the network. With this we have officially changed gears into the replication setup!
Creating Replicas
Primary idea here is to allow a leader based replication in LokiKV. Leader re-election becomes a critical component of such an implementation, and I wish to implement the Paxos algorithm to setup this mechanism. With basic components like WAL, Checkpoints and Control File in place, I have finally started my work on implementing the Paxos Algorithm. If you are not aware of what Paxos is, you can checkout the following video, its really really great at explaining vanilla Paxos, but in layman terms, Paxos allows multiple nodes in a network to act as part of a democratic system. Each node ‘votes’ on which node should become the leader, i.e. all the write operations issued by this node would be the only ones that would be respected. This entire setup is also known as a Quorum. Within each quorum the nodes can perform the following actions:
- Propose: Suggest a value, in this case its own identifier — asking to be elected as a leader
- Acceptors: Nodes that accept the proposed value
- Learners: Nodes that had either not responded to the proposal request, or had refused to accept the value end up getting the value propagated to them if it had been accepted by the majority.
Every node can take up all the above mentioned roles, making Paxos even more interesting to implement. And to be honest, only for this setup I have decided to let go of the above mentioned approach of ‘question everything’ because I just want to see how this algorithm will behave with a system written by me from scratch. Sometimes the joy of making something work ends up making you compromise on certain decisions, an to be honest, we all should sort of try to do this type of stuff often in our personal projects(Please do not cite this at your work!!).
I have a very rough draft implementation for now based on the above mentioned working the architecture below. This basically accounts for:
- Initialization of cluster
- Election of leader if current leader goes down
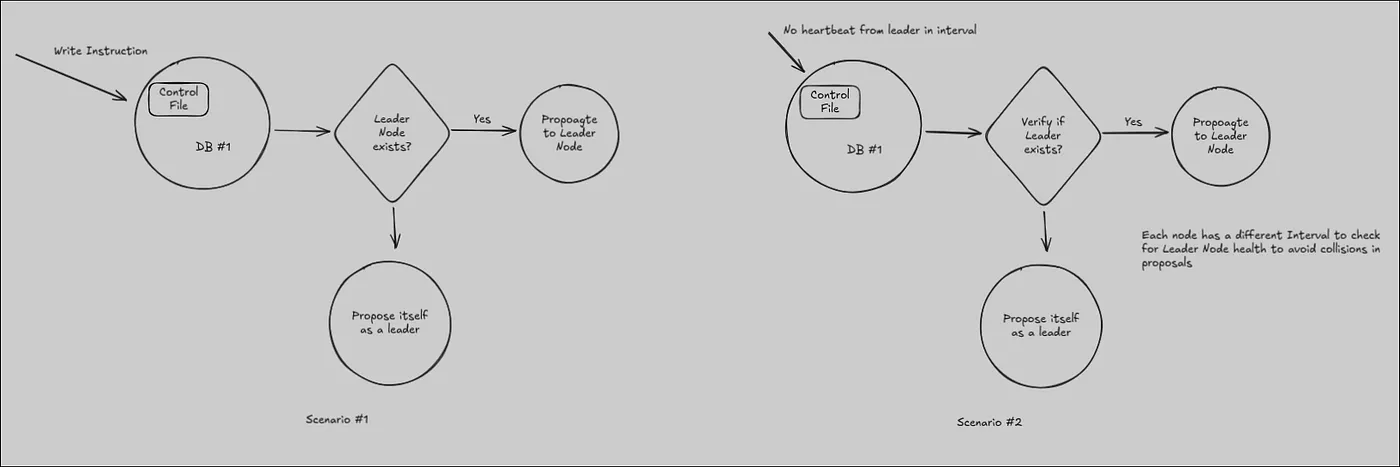
The above diagram is pretty abstract as of now but I have started working on implementing this simple setup. As I make progress with this, I am confident that other caveats might surface up. PS: If you have any suggestions, do post them in the comments below!
I have started working on the initial setup to enable socket level communication in LokiKV server. Primary features required for now include broadcast, a port to listen for broadcasted messages to capture proposals. This setup would eventually power a temporary distributed ledger which will keep track of votes. This is where the broadcast setup will come into picture. Another approach that I am thinking about as of now is setting up a multicast channel and making the nodes subscribe to it. Also one of the primary challenges as of now is to establish how node-discovery will work. For now I plan on keeping the broadcast implementation since its is very easy to discover nodes in the network with it but I am pretty sure I’ll need to switch to a multicast channel soon.
You can checkout the current state of the code here and here.
Some other stuff that I was thinking about
This project needs tests!! I started out LokiKV at a time where I considered tests to be optional(yes people get delusional sometimes) but as I am adding more features, I have realized how much easier it is to just write basic tests for each functionality. They not only let you test the system without the overhead of integrating everything but they also prevent you from causing any regressions.
Another concern as of now is the way locks are being utilized. With the current implementation, the entire db gets locked when a write operation takes place. Ideally only the collection should be locked. This should be a minor refactor since I have more clarity on what needs to be done but I need to pick this up on priority.
Thirdly, the current WAL file setup has an implementation to replay the WAL file but it has not been properly integrated as of now. The startup process just needs to validate if the WAL file exists, load it, replay it, archive it and update the identifier to begin a new WAL file. As of now on startup a new WAL file is created directly without determining if any data needs to be recovered. This would be similar to how PostgreSQL does it but again it would be a much more stripped out version.
Thanks for making it so far!
Well thanks a lot for making it to the end of this Devlog. As you can see stuff has been chaotic but I have been able to make some progress. As this project grows in size, I have realized a lot of things, especially the fact that as and when a project increases in size, you end up rethinking a lot of decisions. As mentioned multiple times, LokiKV is a project that I am using to implement my learnings from various database management systems, especially PostgreSQL and if you wish to do the same you are welcome to open a pull request! I have added multiple features that can be added to this project in the issues section, you are welcome to pick some of them up.
If you feel any of the existing implementations apart from the ones I mentioned in the previous section are inefficient, do raise a PR or create an issue on the GitHub repository. I am really excited to learn from you guys and see how you would have gone implementing certain things!